
flowchart TD A[研究测量数据] --> |数据处理代码| B[分析数据] B --> |数据分析代码| C[计算结果] C --> |数据展现代码| C1[图] C --> |数据展现代码| C2[表格] C --> |数据展现代码| C3[数据摘要] C1 --> D[论文] C2 --> D C3 --> D
可重复性数据分析的概念及其R语言实现
保证数据分析结果可信度的有力工具
R
“可重复性数据分析”的理念假设科学研究中数据生成阶段是可靠且准确的,并鼓励研究者公开原始数据,从而使数据处理与分析过程能够被完整验证,并有机会在相同数据的基础上发现新的科学问题。
1 可重复性数据分析基本概念
1.1 为什么开展可重复性数据分析
重复性是现代科学的基本原则,也是检验科学结论有效性的“金标准”。如果自然界中确实存在某种关联,不同的研究者即使采用不同的方法,也应能够独立地发现这一关联。通常,科学研究会经历一个渐进过程:研究者基于观察提出假设,进行初步探索;随后,通过更大规模的研究验证该假设;再接着,由不同的独立研究团队开展类似研究,并得出相同或相似的结论。这样的累积过程,有助于形成科学界的共识。
当前的科研环境对重复性研究并不友好。此类研究往往需要投入大量时间与资源,但回报有限,且难以获得经费支持,因此很少有研究者愿意仅仅为了验证他人结果而投入精力与资金。随着技术的飞速发展、研究规模的不断扩大、研究周期的延长以及数据复杂度的显著提升,开展可重复性研究或复现他人工作变得愈发艰难。正如吴家睿先生在论文《生命科学研究面临的实验可重复性之危机》中所指出的,这一趋势对科研生态构成了严峻挑战。
技术进步推动了数据规模的指数级增长,这不仅对存储与计算资源提出了更高要求,也为数据共享与重复分析带来了巨大挑战。面对如此庞大的数据集,研究者固然能够解答既定的科学问题,但这些数据往往还蕴藏着探索其他问题的潜力。甚至在分析同一批数据时,不同研究者也可能得出截然不同的结论。
这也对数据处理与分析提出了更高的可重复性要求。基于此背景,Roger D. Peng提出了“可重复性数据分析”概念。该理念假设科学研究中数据生成阶段是可靠且准确的,并鼓励研究者公开原始数据,从而使数据处理与分析过程能够被完整验证,并有机会在相同数据的基础上发现新的科学问题。
因此,研究者在发表论文的同时,应提供完整的数据、分析代码及详尽的方法说明,使他人能够依照相同步骤重现研究结果。这不仅有助于验证科学结论的可靠性,还能促进知识共享、提升研究效率,并减少不必要的重复劳动。
需要注意的是,可重复性数据分析只能验证数据分析过程,无法验证科学问题本身。
1.2 可重复性数据分析流程
可重复性数据分析关注的核心环节,是在获取数据之后到论文正式发表之前的整个过程。研究者在拿到测量数据后,需要对原始数据进行预处理、分析与计算,并通过图表、统计描述等方式进行结果呈现,随后将成果提交期刊,接受审稿人的评估,最终以论文的形式公开发表,使其他研究者能够了解研究者的发现与结论。在这一过程中,需要详细记录从数据处理到论文定稿前的每一个操作步骤,这不仅有助于审稿人评估研究的可靠性,也为后续复现分析提供了保障。实际上,这与实验性研究中要求的完整实验记录类似,只不过这里记录的对象是数据分析的每一个环节,见 图 1。
使用你熟悉的编程语言来记录你的数据分析过程,R,Python或者其它语言。
1.3 为什么要开展可重复性数据分析
可重复性数据分析是研究过程关注和记录数据分析过程的结果,它允许研究者以相同的结果多次重复数据分析过程。
- 帮助研究人员记录数据分析过程
- 使研究人员能够快速修改数据分析的相关内容
- 使重新配置并开展类似的研究更加容易
- 它是科学研究严谨性、可信度和透明度的有力指标
- 增加论文的被引几率
- ……
2 文学编程的概念与可重复性数据分析
文学编程(Literate Programming)是由 Donald Knuth 提出的编程思想,核心理念是——代码不仅是给计算机看的,更是给人看的。它主张将代码与文档紧密结合,把解释性文字、公式、图片和源代码交织在一起,让读者可以像读一篇文章一样理解程序的设计思路和实现细节。
在文学编程中:
- 叙述(Narrative):用自然语言解释你的思路、假设、方法和逻辑。
- 代码(Code):紧跟叙述部分,给出可运行的代码实现。
- 可执行文档:既能输出报告,又能直接运行生成结果。
文学编程(Literate Programming)的理念最初主要应用于技术文档撰写,强调将程序代码与文字说明紧密结合,让代码既能被计算机执行,又便于人类理解。随着这一理念的发展,文学编程被广泛用于科研论文(将数据分析与研究方法直接嵌入文档)、技术教程与教材(边讲解边运行示例代码)、可重复性报告(确保分析过程可追溯)、软件文档(代码与说明同步更新)、博客以及网站等场景。这种方法尤其适合数据分析、算法教学以及需要长期维护和共享的项目,因为它能让代码更易理解、可复用性更高。
3 R语言中如何实现可重复性数据分析
在 R 语言中,文学编程的实现主要有两种方式:Sweave 和 knitr。Sweave 以 LaTeX 作为文档语言,R语言作为编程语言;而 knitr 则采用更为简洁的 Markdown 作为文档语言,同样以R语言作为编程语言。这两种工具都能将文字说明、代码和运行结果整合在同一个文档中,从而有效支持可重复性研究和数据分析。
3.1 Sweave
Sweave采用 Latex做文档语言和R代码作为计算语言,组合成.Rnw文件,Sweave会首先执行R代码,把代码输出和图形结果潜入到LaTex文本中,生成一个纯.tex文件,然后通过通过 pdflatex、xelatex 或 lualatex 将 .tex 文件编译为 .pdf,生成的 PDF 包含排版后的文档和代码输出结果。和 R Markdown 不同,Sweave 完全依赖 LaTeX 进行排版,因此它适合对排版精度要求很高的科研论文,但灵活性比R Markdown小很多。
3.2 R Markdown
Rmarkdown通过knitr包实现艺术编程的理念,从而实现可重复性数据分析。
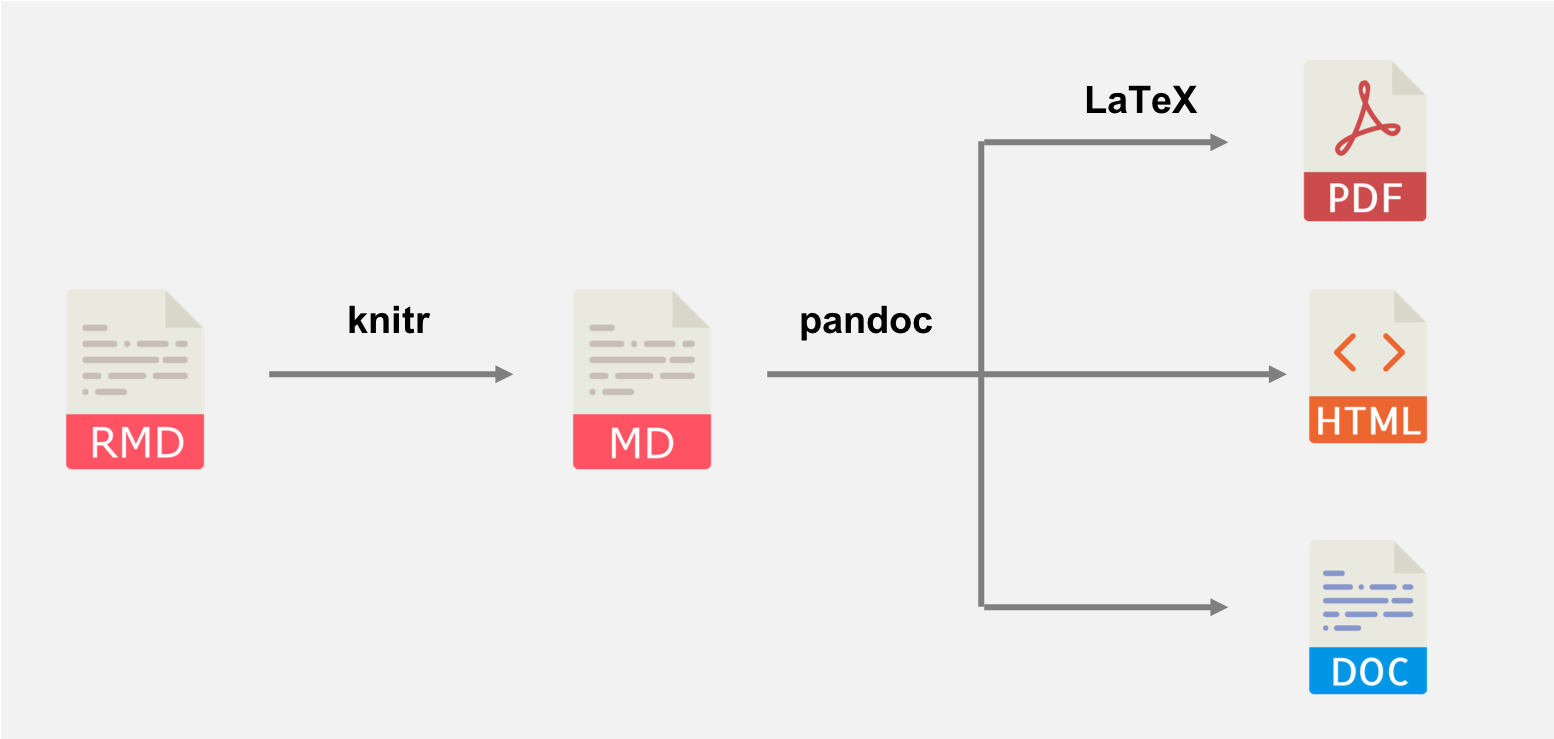
R Markdown将报告文本与统计计算代码无缝整合,实现“一次编写,多种格式输出”,在渲染 R Markdown 时,R 会首先执行文档中的代码块,然后knitr将计算结果与Markdown正文合并,生成一个完整的Markdown文件。接着,利用 pandoc 将其直接转换为 Word 或 HTML 等格式;若需要生成 PDF,则会先将Markdown转换为LaTeX,再通过LaTeX引擎编译为 PDF。
R Markdown 文本以.Rmd和.Rmarkdown为文件后缀,一个完整的 R Markdown 文档通常由三部分组成:
- YAML元数据:定义标题、作者、日期、输出格式等文档信息
- Markdown文本:使用 Markdown 语法编写正文内容
- 代码块:可包含 R、Python 等语言的代码,用于数据处理与分析
YAML 头部(YAML header):
YAML元数据用于定义文档的元数据,例如标题、作者、日期、输出格式等。 在 YAML 头部中,元数据通常以 键值对(key-value pair) 的形式出现:key: value
- 键(key) 表示一个元数据项
- 值(value) 则是该元数据项对应的信息
---
title: My R Markdown Report # 标题
author: Qiong Chen # 作者
output: # 输出格式
html_document:
toc: true # 输出目录
toc_float: true # 目录悬浮
params: # 自定义参数
start_date: '2020-01-01'
end_date: '2020-06-01'
--Markdown作为文档语言:
Markdown是一种轻量级标记语言,由John Gruber于2004年创建,旨在让人们使用易读易写的纯文本格式来编写内容,并能方便地转换成结构化的 HTML、PDF 等格式。
它的主要特点是:
- 语法简洁:使用少量符号(如 #、*、> 等)来表示标题、粗体、引用等格式
- 可读性高:即使不渲染,也能直接阅读纯文本内容
- 跨平台:广泛支持于 GitHub、博客平台、文档系统、笔记软件等
- 易于转换:通过工具(如 pandoc)可导出为 HTML、PDF、Word 等多种格式
一个简单例子:
通过代码块实现统计计算:
在 R Markdown 中,代码块(code chunk) 是用来嵌入并执行代码的区域,可以写 R、Python、SQL 等多种语言的代码。它的作用是把代码、运行结果、图表直接整合到文档中,实现“代码即文档”的理念。
- 代码块的基本结构
代码块用 三个反引号 ``` 包裹,并在起始行加上花括号 {} 指定语言和选项:
speed dist
Min. : 4.0 Min. : 2.00
1st Qu.:12.0 1st Qu.: 26.00
Median :15.0 Median : 36.00
Mean :15.4 Mean : 42.98
3rd Qu.:19.0 3rd Qu.: 56.00
Max. :25.0 Max. :120.00 {r}表示这是 R 语言代码块,也可以写成{python}、{sql}等,使用不同语言。
- 行内代码
除了独立代码块,R Markdown还支持行内代码,可在正文中直接嵌入计算结果,实现数据与文字的无缝融合。计算结果一旦更新,文本描述也会随之自动调整。
渲染后会直接显示 2。
3.3 R Markdown的发展演化
随着 R Markdown 的发展,已形成一个较为完善的生态体系。R 语言社区围绕它开发了众多功能丰富的扩展包,例如:bookdown 用于撰写书籍,blogdown 用于创建博客或网站,posterdown 用于设计学术海报,xaringan 用于制作幻灯片等。

3.4 Quarto
Quarto® is an open-source scientific and technical publishing system built on Pandoc. 基于 Pandoc 的开源科学与技术出版系统。
Quarto是一款跨平台、可独立运行的文档与出版系统,不依赖 R、RStudio 或其他特定编程环境。它继承了 R Markdown 生态中部分扩展包(如 blogdown、bookdown、xaringan)的功能,同时提供统一语法,支持网站、博客、书籍、幻灯片等多种输出格式,大幅降低了学习成本。Quarto 原生支持 R、Python、Julia 和 Observable JS 等多种编程语言,引入了新的 .qmd 文档格式,并调整了代码块选项的书写方式。此外,它内置对科学写作的支持,包括公式、文献引用、交叉引用和图表,使科研文档的撰写更加高效、规范和可复现。
作为 R Markdown 的升级与扩展版本,Quarto在多语言支持、跨平台运行、统一语法、标准化项目管理和科学写作功能等方面均具有显著优势。它适合大型、多语言或跨团队的科研与技术出版项目,能够简化项目配置、便于版本控制,并促进协作与知识共享。
因此,Quarto是实现可重复性数据分析的重要工具。
4 可重复性数据分析内容
可重复性数据分析的关键在于有效记录数据处理、数据分析和数据报告的过程,从而使自己或别人均可以通过记录重复得出相同或相似的结果。
我们可以将数据分析划分为三个阶段:分析前、分析中和分析后。在分析前,安全、有效地管理数据是保证可重复性数据分析的核心。数据通常分为 原始数据 和 分析数据。
- 原始数据:必须安全保存和备份,并保持只读属性,确保内容不被修改。应记录数据的获取途径和方式。例如,通过网络下载的数据需注明下载地址与时间;在R中,最好使用代码自动下载数据,若无法实现,也应保留完整的文档说明。
- 分析数据:应通过代码完整记录从原始数据到分析数据的清洗与转换过程,并检查其是否符合后续建模或其他分析的要求。同时,分析数据需配备说明文档,明确数据结构、变量含义及生成方式。
在分析过程中,代码应遵循社区规范,以保证可读性,并在关键位置添加注释,说明每段代码的功能与目的。许多人都有过类似经历——曾写下的代码,过一段时间便忘了用途。若研究涉及合作者,应共同审阅数据与代码,以减少潜在错误。此外,分析中使用的R包或其他软件,应记录版本信息及计算环境,以便日后复现结果。
分析完成后,应明确分析代码和结果的存放位置,并评估其是否具备对外共享的条件。
